视频压缩:网络传输中为什么需要压缩视频?
主讲人:张哲源(声网Agora 音视频开发工程师)
# 视频需要压缩的原因
最常见的一个像素由8bit大小构成。
一张1920×1080分辨率的高清图片,其大小=1920×1080×8×3=47MB;
而通常视频帧率为30FPS,因此带宽要求约为1.4GB,当前网络情况远远不能满足,因此必须进行视频压缩编码。
当前视频传输流程:
- 采集
- 预处理
- 编码
- 传输
- 解码
- 图像处理
- 显示
# 视频编码的输入
日常会接触到图片是RGB格式,也就是红绿蓝三原色不同比例构成不同的颜色,YUV其实就是RGB的转换。

YUV是由一个亮度分量(Y)和两个色度分量(UV)构成的。
RGB与YUV的转换公式:

# 视频编码的输出
两种应用:
- 实时传输
- 直播平台;
- 在线播放;
- 微信实时通话;
- 本地视频的播放
- 视频编码器保存到本地的是以
h.256为后缀的文件,和音频编码器的本地输出一起封装变成MP4等格式。
- 视频编码器保存到本地的是以
# 视频编码
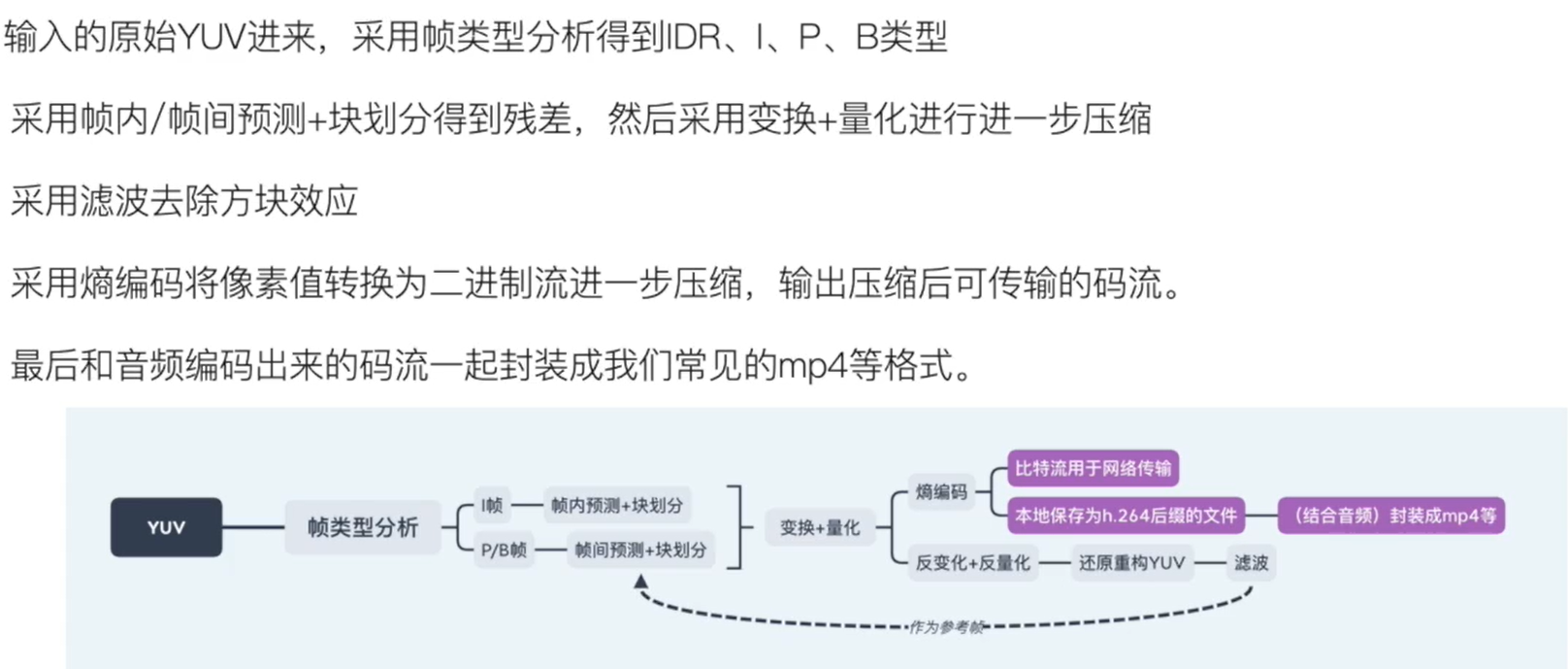
# 帧类型分析
对输入进来的YUV的每一个帧确定一个类型:
- 共分为
I、P、B这三种类型; I帧不会依赖其他帧的信息,也就是自我进行参考的帧;P和B帧:都是会依赖其他帧信息来完成自身预测的帧,区别在于显示序列中P帧是前向参考,B帧是前后双向参考。
理想状态下,一个视频流,从一个帧开始后面轻微运动都是P/B,直到遇到场景切换就再插一个I,如此往复。
一般来说,P/B参考范围不会越过帧。但也有特例,我们可以强行指定P/B参考不允许越过帧,这样的帧我们叫它IDR帧,每个IDR帧的间隔称作一个GOP。
# 帧内/帧间预测
预测原理:
- 大量统计表明:源YUV中两个相邻像素值相等、相似或者缓变概率极大,发生突变的几率是极小。
帧内预测:
- 垂直预测模式,属于帧内预测模式的一种。与它相似的,还有水平预测模式、均值预测模式(也就是4×4的均值填充整个4×4)等。
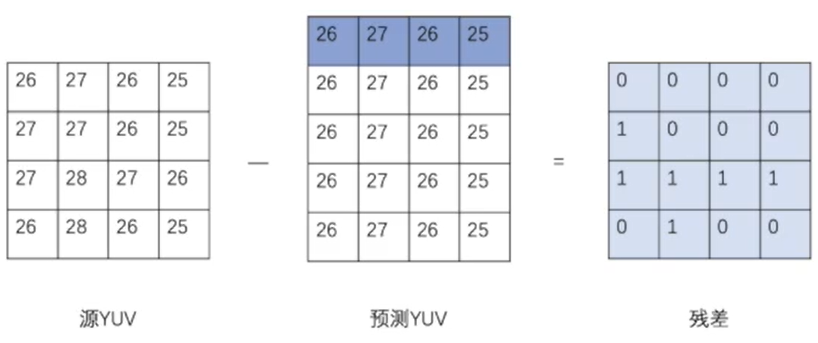
- 码流中传输帧內预测模式标志位、残差即可
帧间预测:
- 以当前块空域相邻的位置,在时域参考帧上的同为块,作为起始点进行规则搜索;
- 直到搜索完找到能够节省码流最大的块作为帧间预测块,当前块到预测块的位移称为运动矢量;
- 码流中传输运动矢量、帧间预测模式标志位、残差即可;
宏块概念:
- 264中把16×16大小的块称作宏块,做帧内/帧间预测的时候可以分成8x8、4×4这样的子块,都是要把它们最能节省码流的预测模式都算岀来,然后比较岀最优秀的划分模式进行传输。
# 变换量化
变换意义:
- 大量统计表明,把经过预测后得到的残差经过
DCT空频变换; - 直流和低频(相对平坦,图像或块中大部分占比)能量集中在左上;
- 高频(细节,图像或块中少部分占比)能量集中在右下;
DCT本身没有压缩作用,但为以后压缩时的取舍,奠定了必不可少的基础。
量化:
- 由于人眼对高频信号不敏感,可以定义这样一个变量QP=5,将变换块中所有的值都除以QP,将QP运算的过程称为量化;
- 这样做进一步节省传输码流位宽,同时主要去掉了高频分量的值,在解码端只需要将变换块中所有的值在乘QP就可以基本还原低频分量。
量化所带来的副作用:
- 量化值越大,丢掉的高频信息就越多,再加上编码器中都是用整形变量代表像素值,所以量化值最大还原的低频信息也会越不准确,即造成的失真就越大,块效应也会越大,视频编码的质量损失主要来源于此。
# 滤波
初步估算块效应边界强度
- 4:边界两边块是帧内预测且块边缘是所在宏块边缘
- 3:边界两边块是帧内预测且块边缘
- 2:边界两边块的残差变换系数包含非零系数
- 1:边界两边块的残差变换系数不包含非零系数,且两块的参考帧或运动向量不同
- 0:边界两边块的残差变换系数不包含非零系数,且两块的参考帧或运动向量相同

# 整体流程